오라클 커서(Cursor)
기본 문법
DECLARE
CURSUR [커서이름] IS [SELECT 문];
BEGIN
OPEN [커서이름];
FETCH [커서이름] INTO [변수];
CLOSE [커서이름];
END;
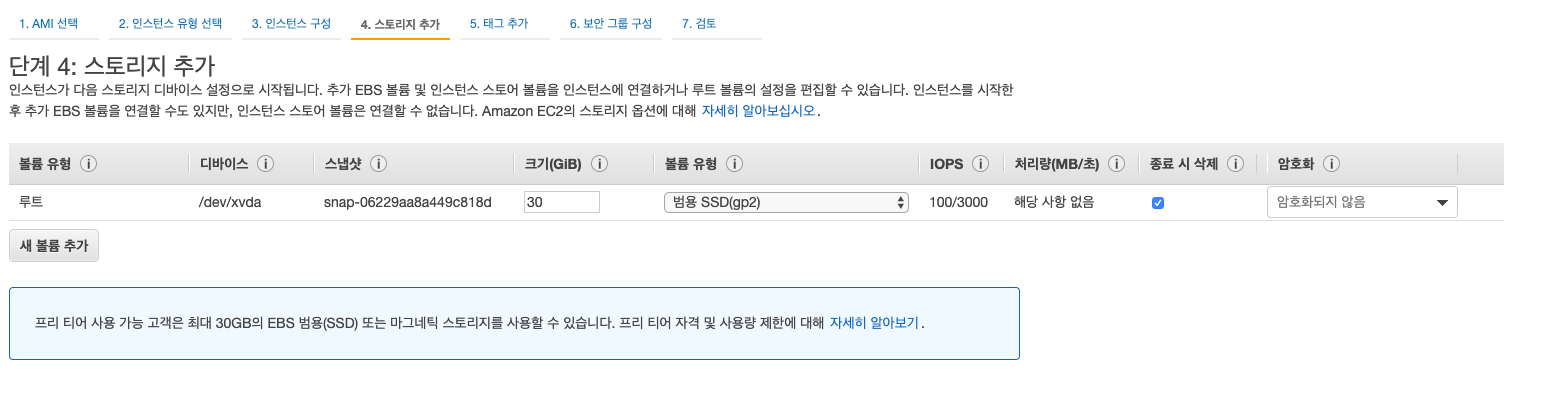
예제 준비
오라클 커서란
커서는 SELECT문 또는 DML문 처리에 대한 정보를 저장하는 전용 SQL 메모리 영역에 대한 포인터이다. DML문의 커서 관리는 오라클 데이터베이스에서 처리하지만, PL/SQL은 커서를 정의하고 조작하여 SELECT문을 실행하는 여러 방법을 제공한다.
일반적인 방법들은 다음과 같다.
- SELECT-INTO 문
- 명시적 커서로부터 가져오기
- 커서 FOR 반복문 사용
- 동적 쿼리에 EXECUTE IMMEDAITE INTO 사용
- 커서 변수 사용
SELECT-INTO문
SELECT-INTO는 SELECT문에서 하나의 행을 가져오는 가장 빠르고 간단한 방법을 제공한다.
SELECT select_list INTO variable_list FROM remainder_of_query
remainder_of_query에는 테이블 또는 뷰, WHERE 절, 기타 절이 포함된다. variable_list의 수와 유형은 select_list의 요소 수와 유형과 일치해야 한다.
SELECT문이 2개 이상의 행을 조회하면 TOO_MANY_ROWS 예외가 발생하고, 조회 데이터가 없으면 NO_DATA_FOUND 예외가 발생한다.
-- * ORACLE Live SQL OE(Order Entry) 스키마를 활용한 SELECT INTO 커서 예제
-- 카테고리 이름이 office1인 데이터의 카테고리 설명을 가져온다.
DECLARE
v_category_desc oe.categories_tab.category_description%TYPE;
BEGIN
SELECT
category_description INTO v_category_desc
FROM oe.categories_tab
WHERE category_name = 'office1';
DBMS_OUTPUT.put_line(v_category_desc);
END;
-- > 결과: capitalizable assets (desks, chairs, phones ...)
-- * NO_DATA_FOUND 예외 발생 예제
DECLARE
v_category_desc oe.categories_tab.category_description%TYPE;
BEGIN
SELECT
category_description INTO v_category_desc
FROM oe.categories_tab
WHERE category_name = 'office0';
DBMS_OUTPUT.put_line(v_category_desc);
END;
-- > 결과: ORA-01403: no data found ORA-06512: at line 4
-- * TOO_MANY_ROWS 예외 발생 예제
DECLARE
v_category_desc oe.categories_tab.category_description%TYPE;
BEGIN
SELECT
category_description INTO v_category_desc
FROM oe.categories_tab;
DBMS_OUTPUT.put_line(v_category_desc);
END;
-- > 결과: ORA-01422: exact fetch returns more than requested number of rows ORA-06512: at line 4
-- CATEGORIES_TAB 테이블에서 카테고리 이름이 office1인 데이터의 행 전체을 가져온다.
DECLARE
v_category_tab oe.categories_tab%ROWTYPE;
BEGIN
SELECT
* INTO v_category_tab
FROM oe.categories_tab
WHERE category_name = 'office1';
DBMS_OUTPUT.put_line(v_category_tab.category_name);
DBMS_OUTPUT.put_line(v_category_tab.category_description);
END;
-- > 결과
/*
office1
capitalizable assets (desks, chairs, phones ...)
*/
-- 상품과 카테고리 테이블을 조인하여 상품 아이디 1797 데이터와 그 카테고리의 특정 정보를 조회한다.
DECLARE
v_category_id oe.categories_tab.category_id%TYPE;
v_category_name oe.categories_tab.category_name%TYPE;
v_product_id oe.product_information.product_id%TYPE;
v_product_name oe.product_information.product_name%TYPE;
BEGIN
SELECT
c.category_id, c.category_name, p.product_id , p.product_name
INTO
v_category_id, v_category_name, v_product_id, v_product_name
FROM oe.categories_tab c
JOIN oe.product_information p ON c.category_id = p.category_id
WHERE p.product_id = '1797';
DBMS_OUTPUT.put_line(
'PRODUCT[' || v_product_id || ']' || v_product_name
|| ' belongs to CATEGORY[' || v_category_id || '] ' || v_category_name
);
END;
-- > 결과: PRODUCT[1797] "Inkjet C/8/HQ" belongs to CATEGORY[12] "hardware2"
- ORA-00947 not enough values: SELECT 조회 결과 컬럼 수보다 변수가 적음
- ORA-00913 too many values: SELECT 조회 결과 컬럼 수보다 변수가 많음
- ORA-06502 PL/SQL: numeric or value error: SELECT 조회 결과 컬럼과 변수의 자료형이 맞지 않음
-- PL/SQL: ORA-00947: not enough values
DECLARE
v_category_id oe.categories_tab.category_id%TYPE;
v_category_name oe.categories_tab.category_name%TYPE;
v_product_id oe.product_information.product_id%TYPE;
v_product_name oe.product_information.product_name%TYPE;
BEGIN
SELECT
c.category_id, c.category_name, p.product_id , p.product_name
INTO
v_category_id, v_category_name, v_product_id
FROM oe.categories_tab c
JOIN oe.product_information p ON c.category_id = p.category_id
WHERE p.product_id = '1797';
DBMS_OUTPUT.put_line(
'PRODUCT[' || v_product_id || '] "' || v_product_name
|| '" belongs to CATEGORY[' || v_category_id || '] "' || v_category_name || '"'
);
END;
-- PL/SQL: ORA-00913: too many values
DECLARE
v_category_id oe.categories_tab.category_id%TYPE;
v_category_name oe.categories_tab.category_name%TYPE;
v_product_id oe.product_information.product_id%TYPE;
v_product_name oe.product_information.product_name%TYPE;
v_add_one VARCHAR2(10 Char);
BEGIN
SELECT
c.category_id, c.category_name, p.product_id , p.product_name
INTO
v_category_id, v_category_name, v_product_id, v_product_name, v_add_one
FROM oe.categories_tab c
JOIN oe.product_information p ON c.category_id = p.category_id
WHERE p.product_id = '1797';
DBMS_OUTPUT.put_line(
'PRODUCT[' || v_product_id || '] "' || v_product_name
|| '" belongs to CATEGORY[' || v_category_id || '] "' || v_category_name || '"'
);
END;
-- ORA-06502: PL/SQL: numeric or value error: character to number conversion error
DECLARE
v_category_id oe.categories_tab.category_id%TYPE;
v_category_name oe.categories_tab.category_name%TYPE;
v_product_id oe.product_information.product_id%TYPE;
v_product_name NUMBER;
BEGIN
SELECT
c.category_id, c.category_name, p.product_id , p.product_name
INTO
v_category_id, v_category_name, v_product_id, v_product_name
FROM oe.categories_tab c
JOIN oe.product_information p ON c.category_id = p.category_id
WHERE p.product_id = '1797';
DBMS_OUTPUT.put_line(
'PRODUCT[' || v_product_id || '] "' || v_product_name
|| '" belongs to CATEGORY[' || v_category_id || '] "' || v_category_name || '"'
);
END;
명시적 커서로부터 가져오기
SELECT INTO는 Oracle DB가 묵시적으로 SELECT문을 위한 커서를 열어 행을 가져오고 작업이 종료되거나 예외가 발생하면 자동으로 커서를 닫는다. 반면 사용자가 명시적으로 커서를 선언하고 열고, 가져오고, 닫는 동작을 할 수 있다. SELECT INTO 문과 달리 커서를 선언부에서 따로 초기화를 해야한다.
OE.ORDERS 테이블에서 SALES_REP_ID로 그룹화하여 ORDER_TOTAL의 합이 많은 순서대로 2000달러씩 보너스를 주는 커서를 프로그래밍해보자. 보너스는 10000달러가 있다고 가정한다.
DECLARE
v_total_bonus INTEGER := 10000;
CURSOR sales_rep_cur
IS
SELECT
*
FROM (
SELECT
sales_rep_id, SUM(order_total) sum_order_total
FROM oe.orders
WHERE sales_rep_id IS NOT NULL
GROUP BY sales_rep_id
)
ORDER BY sum_order_total DESC
;
v_sales_rep_id sales_rep_cur%ROWTYPE;
BEGIN
OPEN sales_rep_cur;
LOOP
FETCH sales_rep_cur INTO v_sales_rep_id;
EXIT WHEN sales_rep_cur%NOTFOUND;
v_total_bonus := v_total_bonus - 2000;
DBMS_OUTPUT.put_line('SALES[' || v_sales_rep_id.sales_rep_id || '] get bonus $2000');
EXIT WHEN v_total_bonus <= 0;
END LOOP;
CLOSE sales_rep_cur;
END;
-- 결과
/*
SALES[161] get bonus $2000
SALES[156] get bonus $2000
SALES[154] get bonus $2000
SALES[158] get bonus $2000
SALES[159] get bonus $2000
*/
커서 FOR 반복문 사용
FOR 반복문을 사용하여 커서를 열고 닫는 것을 생략하고 좀더 간편하게 작성할 수 있다. 위에서 본 예제를 FOR 반복문을 사용하여 프로그래밍 해보자.
DECLARE
v_total_bonus INTEGER := 10000;
CURSOR sales_rep_cur
IS
SELECT
*
FROM (
SELECT
sales_rep_id, SUM(order_total) sum_order_total
FROM oe.orders
WHERE sales_rep_id IS NOT NULL
GROUP BY sales_rep_id
)
ORDER BY sum_order_total DESC
;
BEGIN
FOR sales_rep IN sales_rep_cur
LOOP
v_total_bonus := v_total_bonus - 2000;
DBMS_OUTPUT.put_line('SALES[' || sales_rep.sales_rep_id || '] get bonus $2000'
|| ', sales $' || sales_rep.sum_order_total || ' in this month'
);
EXIT WHEN v_total_bonus <= 0;
END LOOP;
END;
-- 결과
/*
SALES[161] get bonus $2000, sales $661734.5 in this month
SALES[156] get bonus $2000, sales $202617.6 in this month
SALES[154] get bonus $2000, sales $171973.1 in this month
SALES[158] get bonus $2000, sales $156296.2 in this month
SALES[159] get bonus $2000, sales $151167.2 in this month
*/
-- 다른 변수가 없다면 선언부를 생략할 수 있다
BEGIN
FOR sales_rep IN (
SELECT
*
FROM (
SELECT
sales_rep_id, SUM(order_total) sum_order_total
FROM oe.orders
WHERE sales_rep_id IS NOT NULL
GROUP BY sales_rep_id
)
ORDER BY sum_order_total DESC
)
LOOP
DBMS_OUTPUT.put_line('SALESMAN[' || sales_rep.sales_rep_id || ']'
|| ' sales $' || sales_rep.sum_order_total || ' in this month'
);
END LOOP;
END;
-- 결과
/*
SALESMAN[161] sales $661734.5 in this month
SALESMAN[156] sales $202617.6 in this month
SALESMAN[154] sales $171973.1 in this month
SALESMAN[158] sales $156296.2 in this month
SALESMAN[159] sales $151167.2 in this month
SALESMAN[155] sales $134415.2 in this month
SALESMAN[163] sales $128249.5 in this month
SALESMAN[153] sales $114215.7 in this month
SALESMAN[160] sales $88238.4 in this month
*/
동적 쿼리 사용(EXECUTE IMMEDIATE INTO)
EXECUTE IMMEDIATE INTO 문을 사용하여 SELECT문을 즉시 실행하여 변수에 담을 수 있다. Function과 Procedure를 활용하여 동적쿼리를 사용하는 PL/SQL을 프로그래밍 해보자.
실제 환경에서는 동적 쿼리는 SQL 인젝션 위험이 있어 보안에 주의 해야 한다.
-- 단일 결과 동적 쿼리
CREATE OR REPLACE FUNCTION
single_number_value (
table_in IN VARCHAR2,
column_in IN VARCHAR2,
where_in IN VARCHAR2)
RETURN NUMBER
IS
l_return NUMBER;
BEGIN
EXECUTE IMMEDIATE
'SELECT '
|| column_in
|| ' FROM '
|| table_in
|| ' WHERE '
|| where_in
INTO l_return;
RETURN l_return;
END;
-- Function created.
-- SQL Worksheet에서 따로 따로 써서 RUN 해야 한다.
BEGIN
DBMS_OUTPUT.put_line (
single_number_value (
'oe.product_information',
'category_id',
'product_id=1797'));
END;
-- 결과: 12
-- 여러 결과 동적 쿼리 (BULK COLLECT 사용)
CREATE OR REPLACE PROCEDURE
show_number_values (
table_in IN VARCHAR2,
column_in IN VARCHAR2,
where_in IN VARCHAR2)
IS
TYPE values_t IS TABLE OF NUMBER;
l_values values_t;
BEGIN
EXECUTE IMMEDIATE
'SELECT '
|| column_in
|| ' FROM '
|| table_in
|| ' WHERE '
|| where_in
BULK COLLECT INTO l_values;
FOR indx IN 1 .. l_values.COUNT
LOOP
DBMS_OUTPUT.put_line
(l_values (indx));
END LOOP;
END;
-- Procedure created.
BEGIN
show_number_values (
'oe.orders',
'order_total',
'order_total >= 25000
order by order_total desc');
END;
-- 결과
/*
295892
282694.3
268651.8
144054.8
120131.3
103834.4
103679.3
94513.5
92829.4
...
*/
커서 변수
커서 변수는 커서 또는 결과집합을 가리키는 변수이다. 명시적 커서와 달리 커서 변수를 프로시저나 함수의 인자로 전달할 수 있다. 커서 변수는 주로 결과 집합을 응답하는 PL/SQL을 작성할 때 많이 사용된다.
-- 매출이 가장 높은 상품 구하는 함수 생성
CREATE OR REPLACE FUNCTION
find_top_sales_product (
result_count_in NUMBER
) RETURN SYS_REFCURSOR
IS
cur SYS_REFCURSOR;
BEGIN
OPEN cur FOR
SELECT
product_id, sales
FROM (
SELECT
product_id, sum(quantity * unit_price) sales
FROM oe.order_items
GROUP BY product_id
ORDER BY sales DESC
)
WHERE ROWNUM <= result_count_in;
RETURN cur;
END;
-- 함수를 호출하여 상위 10개의 출력하는 PL/SQL
DECLARE
v_products_cur SYS_REFCURSOR;
v_product_id NUMBER;
v_sales NUMBER;
BEGIN
v_products_cur := find_top_sales_product(10);
LOOP
FETCH v_products_cur INTO v_product_id, v_sales;
EXIT WHEN v_products_cur%NOTFOUND;
DBMS_OUTPUT.put_line('Product[' || v_product_id || '] sales $' || v_sales);
END LOOP;
END;
-- 결과
/*
Product[2350] sales $922708.6
Product[3127] sales $364351
Product[2359] sales $180872.8
Product[2252] sales $134079
Product[3003] sales $97464.4
Product[2311] sales $89411.7
Product[3106] sales $82490
Product[2236] sales $79741.2
Product[2289] sales $78099
Product[2245] sales $61908
*/
적절한 방법 선택
- 하나의 행을 조회할 때는 SELECT INTO 문 또는 동적 쿼리를 사용
- 모든 행을 조회할 때 본문이 하나 이상의 DML문을 실행하지 않으면 FOR 반복문 사용
- BULK COLLECT로 가져와야 할 경우 명시적 커서를 사용하지만 각 FETCH에서 조회 결과 수를 제한할 것
- 쿼리 결과가 런타임에 달라질 경우 또는 결과를 PL/SQL이 아닌 환경으로 전달해야할 경우 커서 변수 사용
- 코드를 작성하는 동안 SELECT 문을 완전히 구성할 수 없는 경우에만 동적 쿼리(EXECUTE IMMEDIATE) 사용
참고