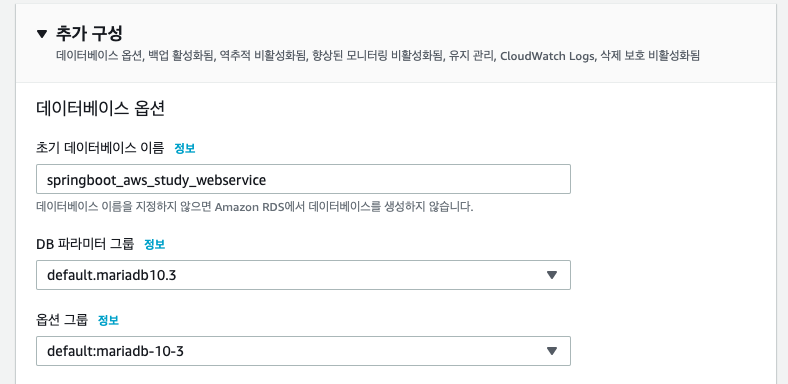
OAuth 2.0

OAuth 2.0 이란?
OAuth 2.0은 인가(Authorization)를 위한 산업표준 프로토콜이다. 2006년에 만들어진 OAuth 프로토콜을 대체한다. OAuth 2.0은 웹 애플리케이션, 데스크톱 애플리케이션, 휴대폰, IoT 장비 등을 위해 특정 인가 절차를 제공하면서 클라이언트 개발자 단순성에 집중한다. 이 표준과 이에 대한 확장은 IETF OAuth Working Group에서 개발되고 있다.
(출처: https://oauth.net/2)
용어 설명
- 인가(Authorization): 인증된 클라이언트에게 허가된 권한을 부여하는 행위
- 인증(Authentication): 클라이언트가 자신이 주장하는 신분을 증명하는 행위
- 인가 서버(Authorization Server): 리소스주인 인증에 성공하고 권한을 얻은 후 클라이언트에게 엑세스 토큰(Access Token)을 발급하는 서버
- 리소스 서버(Resource Server): 보호된 자원(예, 사용자 정보)을 호스팅하는 서버로, 엑세스 토큰을 사용한 요청을 받아 보호된 자원을 응답할 수 있다.
- 리소스 주인(Resource Owner): 보호된 자원에 대한 접근 권한을 부여할 수 있는 객체로, 리소스주인이 사람일 경우 앤드유저(end-user)라고 한다.
- 클라이언트(Client): 리소스주인을 대신하여 권한이 있는 보호된 자원을 요청하는 애플리케이션
인가 승인 방식
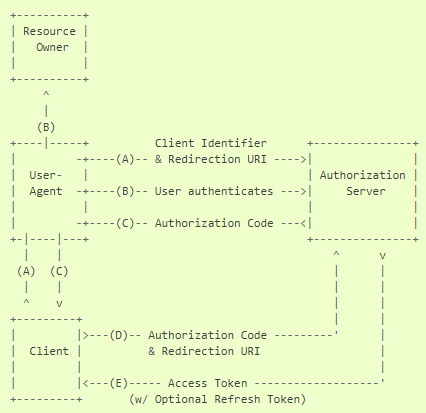
1. Authorization Code
권한 코드(Authorization Code)는 클라이언트와 리소스 주인 사이의 중개 역할을 하는 인가 서버를 통해 얻을 수 있다. 리소스 주인으로부터 직접 인가 요청을 받는 대신, 클라이언트는 리소스 주인을 RFC 2616에 정의된 에이전트(예, 웹 브라우저, 모바일 앱 등)를 통해 인가 서버로 보내고, 권한 코드와 함께 다시 클라이언트로 보냅니다.
리소스 주인을 권한 코드와 같이 클라이언트로 보내기 전에, 인가 서버는 리소스 주인을 인증하고 권한을 얻는다. 리소스 주인은 오직 인가 서버를 통해 인증을 하므로 클라이언트는 리소스 주인의 자격증명에 대해 절대로 클라이언트와 공유되지 않는다.
권한 코드는 중요한 보안 이점을 제공하는데, 클라이언트를 인증하는 기능과 리소스 주인이 사용하는 에이전트(예, 웹 브라우저)에 직접 액세스 토큰을 전달하지 않고 직접 클라이언트에 전송한다.
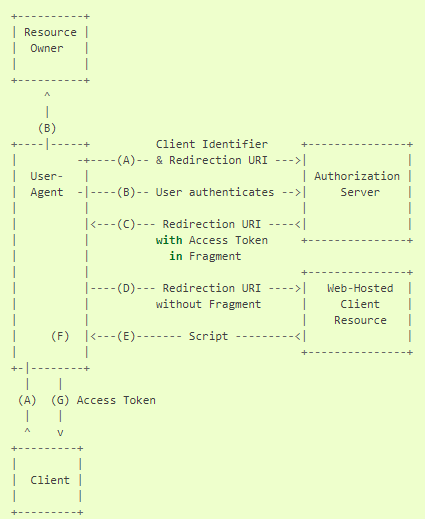
2. Implicit
암시적 승인(Implicit Grant) 방식은 Authorization Code Grant 방식을 단순화한 방식이다. 자바스크립트 같은 스크립트 언어를 사용하여 웹 브라우저에서 구동되는 클라이언트에 최적화되었다. 암시적 승인 절차에서는 권한 코드를 클라이언트에게 발급하는 대신, 리소스 주인의 인가 결과로써 액세스 토큰이 직접 발급된다. 이 권한 유형은 엑세스 토큰을 얻기 위한 중간 자격 증명(예, 권한 코드)이 발급 되지 않기 때문에 암시적 승인이라고 한다.
암시적 승인 절차에서 엑세스 토큰을 발행할 때, 인가 서버는 클라이언트를 인증하지 않는다. 몇몇 경우에는 클라이언트 엑세스 토큰을 클라이언트에 전달하는데 사용된 redirect_uri를 통해 클라이언트 신분을 확인할 수 있다. 엑세스 토큰은 리소스 주인이 사용자 에이전트에 접근하여 리소스 주인 또는 다른 애플리케이션에 노출될 수 있다.
암시적 승인은 엑세스 토큰을 얻는데 필요한 왕복 횟수를 줄이므로 일부 클라이언트의 응답성과 효율성을 향상시킵니다. 그러나 이러한 편리함은 10.3과 10.16에 설명한 것 처럼 보안에 좋지 않을 수 있다.
엑세스 토큰에 대한 검증이 생략되므로 엑세스 토큰이 오용될 수 있다는 얘기.
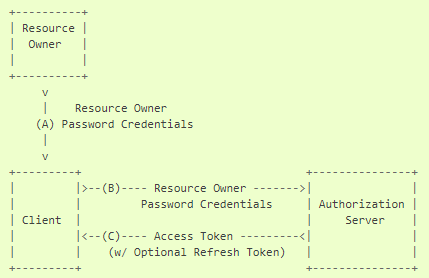
3. Resource Owner Password Credentials
리소스 주인 패스워드 자격증명 승인 방식이다. 일반적으로 엔드 유저의 id, password를 사용하여 직접 인가 절차를 수행하여 엑세스 토큰을 얻는 방식이다. 리소스 주인과 클라이언트 간에 높은 수준의 신뢰도가 있을 경우 사용되어야 하며, 다른 인가 승인 방식은 사용되지 않아야 한다.
이 승인 방식은 비록 클라이언트가 리소스 주인의 자격증명에 직접 접근하게 되지만, 엑세스 토큰을 얻는 한번의 요청에만 자격증명을 사용한다. 클라이언트가 리소스 주인의 자격증명을 저장할 필요성이 없고 긴 유효기간을 가진 엑세스 토큰을 받아 쓸 수 있다.
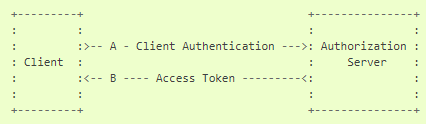
4. Client Credentials
클라이언트 자격증명 인가 방식이다. 권한 범위가 클라이언트가 통제하는 보호된 자원에 제한될 때 또는 보호된 자원이 이전에 인가 서버와 연결된 경우에 클라이언트 자격증명을 사용할 수 있다. 클라이언트 자격증명은 클라이언트가 자신을 대신해 행동할 때 또는 이전에 인가 서버와 연결된 보호자원에 접근하는 요청을 할 때 사용되는 인가 방식이다.
풀어쓰는 OAuth 2.0 인가 절차 이야기
우리가 흔히 경험하는 OAuth 2.0 예는 대표적으로 소셜 로그인을 통한 제 3의 앱 사용이 있다.
예를 들어 애니팡 모바일 앱 게임을 하는데 카카오톡 계정으로 로그인하는 것이다.
이 과정을 조금 풀어쓰면 다음과 같다.
- 카카오톡
인가 서버존재 - 카카오톡 계정정보 담당하는 API 서버(
리소스 서버) 존재 - 써드파티 앱인 애니팡은
클라이언트로써인가 서버에 클라이언트 등록을 한 상태 리소스 주인인 일반 사용자가 애니팡의카카오계정으로 로그인버튼 클릭인가 서버가 설정한 혹은 애니팡이 클라이언트 등록시 설정한승인타입(Grant Type)에 따라 인가 절차 수행- 애니팡은
인가 서버가 사용하는Authorization Endpoint(예, https://dev.kakao.com/oauth/authorize)로 3번에서 등록한client_id와response_type파라미터를 필수로 전송해야한다. 이 때response_type은 표준에서 정한 문자열(code, token 등) 혹은인가 서버가response_type에 설정한 값을 입력해야하며,redirect_uri를 선택적으로 파라미터에 추가할 수 있다.
(https://dev.kakao.com/oauth/authoirze?client_id=anypang-client-id&response_type=code&redirect_uri=https://foward.anypang.com/game/main) 인가 서버가 설정한 사용자 인증(Authentication) 절차를 거쳐(예, 카카오톡 로그인, 제공 권한 동의) 인증한다.- 인증이 완료되면 access_token을 발급하며 애니팡 게임 메인화면(redirect_uri에서 설정)으로 이동한다.
- 애니팡은 카카오톡 계정 API (
리소스 서버)에 사용자 프로필, 친구목록 등을 조회하여 게임 화면에 표시하는데 사용한다.
위의 이야기, 절차 등은 Authorization Grant 방식, 인가서버 설정 방식에 따라 달라질 수 있다. (예시는 Implicit 방식으로 response_type=token 으로 동작한다, 인가코드에 대한 추가 승인 없이 사용자 인증이 완료되면 바로 access_token 발급하는 방식이다.)
참조
'프로그래밍 > 이야기' 카테고리의 다른 글
| [macOS, 맥OS] jEnv로 자바 환경 세팅 (1224) | 2020.06.27 |
|---|---|
| 글을 안 올리는 이유(변명!?) (497) | 2017.06.14 |
| 개발자 자기계발 및 실력향상 노하우 (프로젝트가 서쪽으로 간 까닭은, 프로그래머의 리더십) (481) | 2016.03.17 |